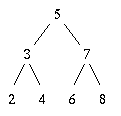In the next several lectures, we'll be thinking about multiple representations, different ways to implement the same abstraction. We've already seen different ways to implement some ADT's. For example, we discussed the implementation of stacks and queues in terms of ordinary linked lists, and then saw how to implement the same abstraction in terms of circular lists.
Part of the software design process is choosing an appropriate representation for an ADT once the interface has been defined. Factors influencing this decision include:
The answers are not always easy. There are space-time tradeoffs, meaning that one implementation may use little time but require a lot of space, while another implementation may use little space but require a lot of time. Also, there may be tradeoffs between methods of the ADT. For example, one implementation of a relation may support fast insertion but provide slow lookup, while another implementation may do exactly the reverse. The choice, then, might depend on whether one expects to do a lot of inserts and few lookups, or the other way around.
BaseNumberThere are multiple ways to represent almost any kind of data, even all the way down to the seemingly most primitive. For example, even numbers can be represented in different ways. The abstract quantity 5 can be represented:
5, V, |||||, fivejust to name a few.
The choice of representation of numbers has great impact on the efficiency with which computations may be carried out. For example, people today generally use the decimal system (base 10, with digits 0-9) to represent numbers. If we still used the roman numeral system, imagine how much more difficult it would be to make technological progress!
Inside a computer, it turns out that representing integers using base 2 (as opposed to the base 10 or decimal numbers) is more efficient. This is because each storage element inside a computer holds a high or low voltage that can be thought of as representing a 0 or 1, the two digits used in base 2 number representation. For example,
123 base 10 = 1 · 102 + 2 · 101 + 3 = 1 · 26 + 1 · 25 + 1 · 24 + 1 · 23 + 0 · 22 + 1 · 21 + 1 = 1111011 base 2
Note that although the numbers are stored as base 2 inside the machine, Java prints them out in base 10 for "human consumption."
To explore the idea of converting between different number representations, let's create an ADT that can be used to represent numbers in different bases. This will also give us a chance to develop some algorithms for converting to and from base 10. Although we could implement these algorithms recursively, we'll implement them iteratively to provide more practice with iteration.
First, theBaseNumber ADT interface:
| method | parameters | mutates | returns |
|---|---|---|---|
| constructor | int value | creates representation of value in base 10 | (object reference) |
toInt |
an int whose value is the same as the number being represented | ||
toBase |
int b (0<b<10) | a new BaseNumber object representing the same
value, but in base b |
|
toString |
"XXXX base X" |
We could also have some methods for adding and multiplying
BaseNumbers, but let's stick with the above methods
for now.
For our internal representation of BaseNumber
objects, let's store the base and a list of digits representing
the number. To create new base numbers in different bases,
we'll need a second constructor that takes in the base and the
digit list.
public class BaseNumber {
int base;
Digit list;
public BaseNumber(int value) {
base = 10;
list = listInBase(10, value);
}
BaseNumber(int base, Digit list) {
this.base = base;
this.list = list;
}
Digit listInBase(int base, int n) {
if (n == 0)
return new Digit(0,null);
else {
Digit ls = null;
while (n != 0) {
ls = new Digit(n % base, ls);
n /= base;
}
return ls;
}
}
An example conversion of an int to a list in base 10:
| base | int n | n % 10 | digit.list |
|---|---|---|---|
| 10 | 123 | 3 | (3) |
| 12 | 2 | (2 3) | |
| 1 | 1 | (1 2 3) | |
| 0 |
| base | int n | n % 2 | digit.list |
|---|---|---|---|
| 2 | 123 | 1 | (1) |
| 61 | 1 | (1 1) | |
| 30 | 0 | (0 1 1) | |
| 15 | 1 | (1 0 1 1) | |
| 7 | 1 | (1 1 0 1 1) | |
| 3 | 1 | (1 1 1 0 1 1) | |
| 1 | 1 | (1 1 1 1 0 1 1) | |
| 0 |
public int toInt() { // uses Horner's method
Digit ls = list;
int result = 0;
while (ls != null) {
result = (result * base) + ls.number;
ls = ls.next;
}
return result;
}
An example conversion of 11110112 to an int:
| ls | result |
|---|---|
| 1111011 | 0*2+1 = 1 |
| 111011 | 1*2+1 = 3 |
| 11011 | 3*2+1 = 7 |
| 1011 | 7*2+1 = 15 |
| 011 | 15*2+0 = 30 |
| 11 | 30*2+1 = 61 |
| 1 | 61*2+1 = 123 |
Effectively, we're computing the value at each "place" and summing:
1 · 26 + 1 · 25 + 1 · 24 + 1 · 23 + 0 · 22 + 1 · 21 + 1
but we're using Horner's method to save computation.
public BaseNumber toBase(int b) { // 2 <= b <= 10
return new BaseNumber(b, listInBase(b, toInt()));
}
public BaseNumber plus(BaseNumber x) {
return new BaseNumber(toInt() + x.toInt());
}
public BaseNumber times(BaseNumber x) {
return new BaseNumber(toInt() * x.toInt());
}
public String toString() {
return ("" + list + " base " + base);
}
Notice that this uses Digit's
toString method, which doesn't put spaces between
the digits.
}
class Digit {
int number;
Digit next;
Digit(int n, Digit next) {
number = n;
this.next = next;
}
public String toString() {
if (next == null)
return "" + number;
else
return "" + number + next;
}
}
An alternative way to implement the class would be to store the
base and the integer value of the number as instance variables.
Then the only non-trivial method would be toString,
which would be similar to the listInBase method
above.
SetAs we have seen, one of the important benefits of data abstraction is encapsulation, hiding the internal representation of the data behind an abstraction barrier consisting of public methods. This encapsulation allows us to change the internal representation without changing the semantic behavior of the object. One motivation for changing the internal representation is to improve performance (efficiency).
In the next example, we'll consider three different internal representations of a set ADT, and we'll consider the impact of each representation on the performance. In particular, we'll look at time requirements for executing the various methods with each choice of representation.
First, let's define the interface for the set ADT:
| method | parameters | mutates | returns |
|---|---|---|---|
| constructor | creates an empty set | (object reference) | |
isEmpty |
true iff set is empty | ||
insert |
x |
inserts x into the set (if not already an
element) |
|
delete |
x |
removes x from the set (if it was there
before) |
|
hasElement |
x |
true iff x is an element of the set |
|
union |
set T |
inserts all elements of T into the set |
|
intersection |
set T |
deletes all elements not in T |
|
difference |
set T |
deletes all elements in T |
|
sizeOf |
number of elements in set | ||
toString |
string representation of the set |
Recall: A set does not contain duplicate items. (A multiset is like a set, but may contain duplicate items.)
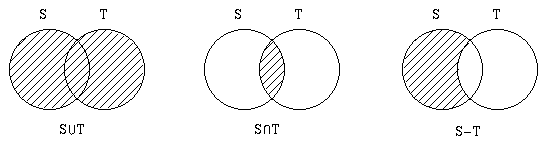
Since our concern is choice of representation, we want to explore various possible representations and make comparisons. To do these comparisons, it is not necessary to do a complete implementation. Instead, we will:
Pseudocode is an informal notation with code-like structure. It is used to get the essentials of an algorithm on paper without taking the time to deal with the language-specific details. Often. people explain algorithms to each other because it's easier to read and is not dependent on knowledge of a particular language. You can think of pseudocode as an abstraction of an algorithm implementation.
Let's suppose that the methods for which we really care most about efficiency are: insert, delete, and intersection. In general, one would care most about the methods that we expect to be used more often.
We can create a table in which to make comparisons of the relative efficiency of the best algorithms we can find for each of three representations.
| Method | Representation A | Representation B | Representation C |
|---|---|---|---|
| insert | |||
| delete | |||
| intersection |
In each square of the table, we will fill in the time required to perform the given method using the best algorithm we can think of for the given representation.
As we do our analysis, we will make the following assumptions:
We are already familiar with linked lists of numbers, so let's
first consider how we might implement the insert, delete, and
intersection methods using linked lists. We'll use the
ListOfInts ADT we implemented earlier as our
internal representation.
Pseudocode will be used to describe the algorithms.
For insert, we'll walk to the end of the list
looking for the given number. If it's not there, we'll put it
at the end.
Notice that if the element isn't already in the set, we must examine all of the elements. Since our analysis is to be done for the case of inserting a new item into a set of n elements, we can write "n" in the table.
For delete, we'll use a similar strategy, but this
time if we find the number, we'll take it out.
For delete, we're interested in the cost of deleting
an existing set element. Assuming deletion of a random element,
we can expect to go about half way down the list, on average. So
we can write n/2 in the table.
For intersection, we want to delete all elements
of our set that aren't also elements of the given set.
For each item in the list, we check to see if the item is in
the other list. We haven't written the hasElement
method, but we know that this check requires looking through the
whole list if the item isn't there. Since we're measuring the
case where the intersection is empty, we need to examine
n2 items.
Let's see if we can improve performance by keeping the list in sorted order, least to greatest.
For insert, we'll do it like before, but we can
stop "early," as soon as we see an element greater that (or
equal to) the one we're inserting.
On average, we'll go halfway down the list, even inserting a new element, so n/2 goes in the table.
For delete, a similar strategy:
Again, we expect to go halfway down the list, even if the element isn't in the set.
For intersection, how can we best exploit the fact that the two
lists are in sorted order? If we call hasElement
for each item to see if it's in the other set, then we have to
look through the other set n times. However, knowing
that the lists are sorted, we can walk down both lists
simultaneously, saving the elements in common and discarding the
others. That is, we'll use a "two finger" approach, where one
finger points to an element in each list.
If the element in S is smaller, we delete it since it's not in T. If the element in T is smaller, we skip over it. If the elements are equal, we move forward in both lists.
intersection(set t)truncate method that removed all the items after
the marker. How would you write the truncate method and use it
into the code above?
The methods insert, delete, and
hasElement all depend on being able to find the
presence (or absence) of a given element, and other elements may
be implemented in terms of these. Therefore, let's think about
the way we've been finding elements by looking through the list.
In the unordered list, we had to look all the way through the
list. In the unordered list representation, we had some
improvement, on average looking at only half the list.
But when you look for a name in the telephone book, do you start at the first name in the book and read each name until you get to the one you want? Of course not. More likely, you start somewhere in the middle and move forward or back in smaller and smaller chunks until you find the right page.
So what we'd like is a data structure that lets us start somewhere in the "middle" and then move left or right in large chunks, narrowing the search as we go. One data structure that offers this kind of capability is known as a binary search tree.
Let's use this structure for our set of numbers. Each item (node) of our binary search tree contains three things:
For each node, all elements in the left subtree are smaller and all elements in the right subtree are greater.Examples: Insertion order matters!
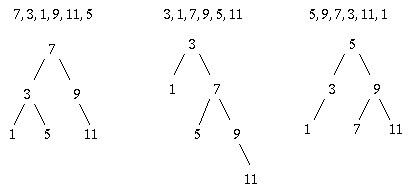
The first value inserted goes in the top node, called the root. Nodes without children are called leaves.
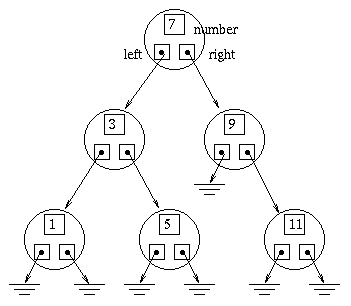
We can define a tree node as follows:
class TreeNode {
int number;
TreeNode left;
TreeNode right;
TreeNode(int n, TreeNode l, TreeNode r) {
number = n;
left = l;
right = r;
}
}
So, we'll build up trees out of TreeNode objects as
follows:
To insert, we go down the tree, moving left or right at each level until we either find the number or reach the bottom and insert a new node.
insert(x)Alternatively, we can do this recursively:
insert(x)If we assume the tree is balanced (as "bushy" as possible), then the nth level contains 2n nodes, so a tree with n nodes contains approximately log2n levels (the power of 2 to get n).
Delete is tricky. We can't just pluck a node out of the middle of a tree because it may have two children. Where would they go?
For example, suppose we want to delete 3 from
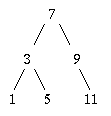
If we just removed the 3, we'd have to do something with the 1 and the 5. But 7 only has room for one left child. We could just re-insert all descendants of 3, but there could, in general, be a lot of them, so that could take too much time.
What if we replace the 3 by some other value further down in the tree? We must maintain the invariant that:
For each node, all values in the left subtree are smaller, and all values in the right subtree are greater.
So we want a value greater than all the values in the left subtree and less than all values in the right subtree. Well, we know that all values in the left subtree are less than all values in the right subtree, so the greatest value in the left subtree will work, as will the least value in the right subtree.
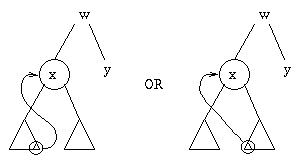
Suppose we decide to use the greatest value in the left subtree. What happens if there isn't a left subtree? Then we can just replace the deleted node by the right subtree.
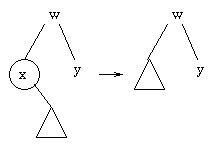
Now what if x has no children? Then we can just delete x.
The only remaining question: How do we find the largest element in the left subtree? Kepp moving right in that subtree as far as possible.
delete(x)Alternatively, we could delete the rightmost node when we find it, but we must be sure to return the value for use higher in the tree.
We'll implement intersection recursively. At each node, if it's not in the other set, we remove it and recurse. Otherwise, we recurse on the left and right subtrees, intersecting each with the given set.
intersection(set T)Assuming balanced trees, hasElement takes
log2n time. Since intersection calls
hasElement for each node. So far we have
n·log2n. However, each
deletion takes up to 2 log2n time, one
log2n factor to find the largest node in the
left subtree and one log2n factor to delete
it from the subtree. So, all together we have
3n log2n time.
Let's go back and look at the comparison table.
| Set ADT Method | Unordered List | Ordered List | Binary Search Tree | ||||||
|---|---|---|---|---|---|---|---|---|---|
| n=32 | n=1024 | n=32 | n=1024 | n=32 | n=1024 | ||||
| insert | n | 32 | 1024 | n/2 | 16 | 512 | log2n | 5 | 10 |
| delete | n/2 | 16 | 512 | n/2 | 16 | 512 | 2 log2n | 10 | 20 |
| intersection | n2 | 1024 | 1048576 | 2n | 64 | 2048 | 3n log2n | 480 | 30720 |
Clearly, the ordered list beats the unordered list. But what about the other two? Really, it depends on how many of each type of operation you expect.
Another thought: Could we use the binary search tree but convert to ordered lists for taking intersections? This would give us a hybrid implementation.
First, let's think about how much it would help. We'd have to
So, all together, we'd have n·(log2n + 3). For n=32 and n=1024, the costs would be 256 and 13312, some improvement. Of course, we'd have to be careful about our assumption of balanced trees.
How can we convert a binary search tree to an ordered list? We can create an empty list, and insert the elements in order. We'll do this recursively, starting at the root. Each node will make a recursive call to insert all the elments less than itself (the left side), then it will insert itself, and finally it will make another recursive call to insert all the elements larger than itself (the right side). This is known as an in-order traversal.
ListOfInts toList()