|
General Weighted Fairness and its Support in Explicit Rate Switch Algorithms 1 2
Bobby Vandalore, Sonia Fahmy, Raj Jain, Rohit Goyal, Mukul Goyal
The Ohio State University
Department of Computer and Information Science
2015 Neil Avenue Mall, Columbus, OH 43210-1277
{vandalor, fahmy, jain, goyal, mukul}@cse.wustl.edu
This paper gives a new definition of general weighted (GW) fairness and shows how this can achieve various fairness definitions, such as those mentioned in the ATM Forum TM 4.0 specifications. The GW fairness can be achieved by calculating the ExcessFairshare(weighted fairshare of the left over bandwidth) for each VC. We show how a switch algorithm can be modified to support the GW fairness by using the ExcessFairshareterm. We use ERICA+ as an example switch algorithm and show how it can be modified to achieve the GW fairness. For simulations, the weight parameters of the GW fairness are chosen to map a typical pricing policy. Simulations results are presented to demonstrate that, the modified switch algorithm achieves GW fairness. An analytical proof for convergence of the modified ERICA+ algorithm is given in the appendix.
Keywords:ATM switch algorithms, pricing policy, ABR service, traffic management.
Introduction
The asynchronous transfer mode (ATM) is the chosen technology to implement Broadband Integrated Services Digital Network (B-ISDN). Different traffic characteristics ranging from non real-time to real-time are supported in ATM through its various service categories (CBR - constant bit rate, rt-VBR - real-time variable bit rate, nrt-VBR - non real-time VBR, ABR - available bit rate, UBR - unspecified bit rate). The ATM Forum is currently in the process of standardizing the Guaranteed Frame Rate (GFR) service category. The International telecommunication union (ITU-T) defines similar service categories for ATM.
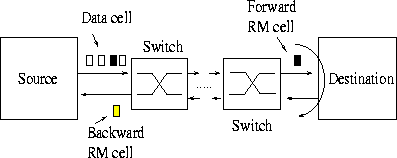
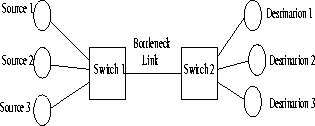
The ABR service category is the only service category which uses closed-loop feedback for flow control. All other service categories have open loop flow control. In ABR, one resource management (RM) cell is sent for every Nrm-1 (value Nrmparameter is usually 32) data cells by the source. The source indicates its current source rate in the RM cell. The RM cell is turned around at the destination and sent back to the source (Figure 1). The switches along the RM cell path indicate the current maximum rate which they can support in the explicit rate field of the RM cell. The sources adjust their rates accordingly.
|
|
To get a guarantee for the minimum amount of service the user can specify a minimum cell rate (MCR) in ATM ABR service. The ABR service guarantees that the allowed cell rate (ACR) is never less than MCR. When MCR is zero for all sources, the available bandwidth can be allocated equally among the competing sources. This allocation achieves max-min fairness. When MCRs are non-zero, ATM Forum TM 4.0 specification [ 1] recommends, other definitions of fairness that allocate the excess bandwidth (which is, available ABR capacity less the sum of MCRs) equally among sources, or proportional to MCRs. In this paper, we give a different definition of sharing the excess bandwidth using predetermined weighted than one recommended in ATM Forum specifications [ 1]. In the real world, the users prefer to get a service which reflects the amount they are paying. The pricing policy requirements can be realized by appropriately mapping the policy to the weights associated with the sources.
The specification of the ABR feedback control algorithm (switch algorithm) is not yet standardized. The earliest algorithms used binary feedback techniques [ 2]. Distributed algorithms [ 3] that emulated a centralized algorithm were proposed in [ 4, 5]. Improved, simpler distributed algorithms which achieved max-min fairness were proposed in [ 6, 7, 8, 9, 10, 11]. Recently, a discussion on generalized definition of max-min fairness and its distributed implementation is given in [ 12, 13]. A weight-based max-min fairness policy and its implementation in ABR service is given in [ 14]. The fairness in the presence of MCR guarantees is discussed in [ 15, 16].
In this paper we generalize the definition of the fairness, by allocating the excess bandwidth proportional to weights associated with each source. We show how a switch scheme can support non-zero MCRs and achieve the GW fairness. As an example, we show how the ERICA+ [ 6] switch scheme can be modified to support the GW fairness.
The modified scheme is tested using simulations with various network configurations. The simulations test the performance of the modified algorithm, with different weights, using a simple configuration, a transient source configuration, a link bottleneck configuration, and a source bottlenecked configuration. Scalability and robustness are tested using a configuration with hundred TCP sources and a background VBR connection carrying long range dependent traffic. These simulations show that the scheme realizes various fairness definitions in ATM TM 4.0 specification, that are special cases of the generalized fairness.
Section 2discusses the GW fairness definition and shows how the various other definitions of fairness can be realized using this general definition. Then, we show how a switch scheme can achieve general fairness. As an example, we show how ERICA+ is modified to support the GW fairness. An analytical proof of convergence for the modified algorithm in the appendix. Simulation configurations and the results for the modified algorithm are given next. Finally, we give our conclusions and discuss some future work.
General weighted fairness: Definition We first define the following parameters:
The general weighted fair allocation is defined as follows:
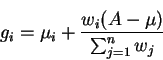
This is a special case of general weighted fairness with
![]() = 0, and wi= c, where c is a constant.
= 0, and wi= c, where c is a constant.
by assigning equal weights we achieve the above fairness.
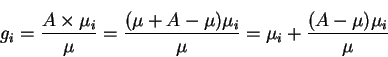
By assigning
![]() we can achieve the above fairness.
we can achieve the above fairness.
Relationship to pricing/charging policies
In real world users expect a service related to the price they are paying for the service. In this section we discuss a simple pricing policy and arrive at an weight function to support such a policy.
Consider a very small interval Tof time. The charge Cthat a customer pays for using a network during this interval is a function of the number of bits W that the network transported successfully:
Where, R= W/Tis the average rate.
It is reasonable to assume that f() is a non-decreasing function of W. That is, those sending more bits do not pay less. The function f()should also be a non-increasing function of time Tor equivalently a non-decreasing function of rate R.
For economy of scale, it is important that the cost per bit does not increase as the number of bits goes up. That is, C/Wis a non-decreasing function of W.
Mathematically, we have three requirements:
One simple function that satisfies all these requirements is:
Here, cis the fixed cost per connection; wis the cost per bit; and ris the cost per Mbps. In general, c, w, and rcan take any non-negative value.
In the presence of MCR, the above discussion can be generalized to:
Where, Mis the MCR. All arguments given above for Rapply to Malso except that the customers requesting larger Mpossibly pay more. One possible function is:
where, mis dollars per Mbps of MCR. In effect, the customer pays r+mdollars per Mbps up to Mand then pays only rdollars per Mbps for all the extra bandwidth he/she gets over and above M.
Consider two users with MCRs M1and M2. Suppose their allocated rates are R1and R2and, thus, they transmit W1and W2bits, respectively. Their costs are:
Cost per bit (C/W) should be a decreasing function of bits W. Thus, if
![]() :
:
Since Ri= Wi/T, we have:
Where a(=c/m) is the ratio of the fixed cost and cost per unit of MCR.
Note that, the allocated rates should either be proportional to a+MCR or be a non-decreasing function of MCR. We have chosen to use a+MCR as the weight function in our simulations.
General weighted fair allocation problem In this section we give the formal specification of the general weighted fair allocation problem, and give a motivation for the need of a distributed algorithm.
The following additional notation is necessary:
The GW fair problem is to find the rate vector equal to the GW fair allocation, i.e.,
![]() . Where
. Where
![]() is calculated for each link las defined in the section
2.
is calculated for each link las defined in the section
2.
Note the 5-tuple
![]() represents an instant of the bandwidth sharing problem. When all weights are equal the allocation is equivalent to the general max-min fair allocation as defined in [
12,
13]. A simple centralized algorithm for solving the above problem would be to first, find the correct allocation vector for the bottleneck links. Then, solve the same problem of smaller size after deleting bottleneck links. A similar kind of centralized, recursive algorithm is discussed in [
13]. Centralized algorithm implies that all information is known at each switch, which is not feasible, hence a distributed algorithm is necessary.
represents an instant of the bandwidth sharing problem. When all weights are equal the allocation is equivalent to the general max-min fair allocation as defined in [
12,
13]. A simple centralized algorithm for solving the above problem would be to first, find the correct allocation vector for the bottleneck links. Then, solve the same problem of smaller size after deleting bottleneck links. A similar kind of centralized, recursive algorithm is discussed in [
13]. Centralized algorithm implies that all information is known at each switch, which is not feasible, hence a distributed algorithm is necessary.
A typical ABR switch scheme calculates the excess bandwidth capacity available for best effort ABR after reserving bandwidth for providing MCR guarantee and higher priority classes such as VBR and CBR. The switch fairly divides the excess bandwidth among the connections bottlenecked at that link. Therefore, the ACR can be represented by the following equation.
ExcessFairshareis the amount of bandwidth allocated over the MCR in a fair manner.
In the case of GW fairness, the ExcessFairshareterm is given by:
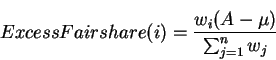
If the network is near steady state (input rate = available capacity), then the above allocation enables the sources to attain the GW fairness. The ATM TM 4.0 specification mentions that the value of (ACR- MCR) can be used in the switch algorithms. We use this term to achieve the GW fairness. We have to ensure the (ACR- MCR) term converges to ExcessFairsharevalue. We use the notion of activity levelto achieve the above objective [ 17]. A connection's excess activity level(EAL(i)) is defined as follows.
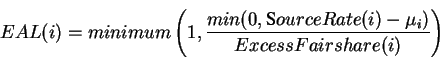
SourceRate(i) is the rate at which the source is currently transmitting data. Note that,
SourceRate(i) is the ACR(i) given as the feedback rate earlier by the switch. The excess activity level indicates how much of the
ExcessFairshareis actually being used by the connection. Excess activity level is zero if
SourceRate(i) is less than
![]() . The activity level attains the value of one when the
ExcessFairshareis used by the connection. It is interesting to note that using activity level for calculating is similar to the Charny's [
18]
consistent markingtechnique, where the switch marks connections which have lower rate than their
advertised rate. The new advertised rate is calculated using the equation:
. The activity level attains the value of one when the
ExcessFairshareis used by the connection. It is interesting to note that using activity level for calculating is similar to the Charny's [
18]
consistent markingtechnique, where the switch marks connections which have lower rate than their
advertised rate. The new advertised rate is calculated using the equation:
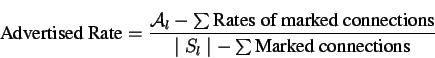
The activity level inherently captures the notion of marking, i.e., when a source is bottlenecked elsewhere, then activity level times the fairshare (based on available left over capacity) is the actual fairshare of the bottleneck source. The computation of activity level can be done locally and is an O(1) operation, compared to O(n)computations required in consistent marking [ 18].
We expect that the links use their ExcessFairshare, but this might not be case. By multiplying the weights by the activity level, and using these as the weights in calculating the ExcessFairsharewe can make sure that the rates converge to the GW fairness allocation. Therefore, the ExcessFairshareshare term is defined as:
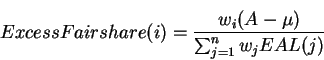
Note that, wiis not multiplied by EAL(i) in the numerator, since we desire to attain a value of EAL(i) = 1 for all sources and give excess bandwidth in proportion to the weights. Due to this, sources which have not yet achieved their fairshare are asked to increase their rate to ExcessFairShare. Rate of sources which are bottlenecked elsewhere are not affected. The rate of such a source depends only the explicit feedback rate which it receives from switches at which it is bottlenecked. Connections which are at bottlenecked at sources also receive the correct amount of ExcessFairShare.
An switch algorithm can use the above ExcessFairshareterm to achieve the GW fairness. In the next section we show how the ERICA+ switching algorithm is modified to achieve the GW fairness.
Example modifications to a switch algorithm The ERICA+ algorithm operates at each output port of a switch. The switch periodically monitors the load on each link and determines a load factor (z), the available ABR capacity, and number of currently active sources or VCs. The measurement period is the ``Averaging Interval''. These measurements are used to calculate the feedback rate which is indicated in the backward RM (BRM) cells. The measurements are done in the forward direction and the feedback is given in the backward direction. The complete description of the ERICA+ algorithm can be obtained from [ 6].
The ERICA+ algorithm uses the term FairShare, which is the bottleneck link capacity divided by the active number of VCs. It also uses a
MaxAllocPreviousterm, which is the maximum allocation in the previous ``Averaging Interval''. This term is used to achieve max-min fairness. We modify the algorithm by replacing the FairShareterm by
ExcessFairshare(i) and adding the MCR (
![]() ). The keys steps in ERICA+ which are modified to achieve the GW fairness are shown below:
). The keys steps in ERICA+ which are modified to achieve the GW fairness are shown below:
Algorithm A
At the end of Averaging Interval:

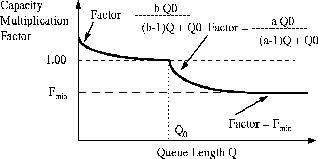
The Fractionterm is dependent on the queue length [
19]. When the Fractionis less than one,
![]() is used to drain the queues. A simple choice is to use a constant queue control function (CQF), where the Fractionis set to a value less than 1, say 0.95. The remaining 5% of the link capacity is used for queue draining. Another option is to use a dynamic queue control function (DQF). In DQF, the Fractionvalue is one for small queue lengths and drops sharply as queue length increases. ERICA+ uses an hyperbolic function for calculating value of the Fraction(Figure
2).
is used to drain the queues. A simple choice is to use a constant queue control function (CQF), where the Fractionis set to a value less than 1, say 0.95. The remaining 5% of the link capacity is used for queue draining. Another option is to use a dynamic queue control function (DQF). In DQF, the Fractionvalue is one for small queue lengths and drops sharply as queue length increases. ERICA+ uses an hyperbolic function for calculating value of the Fraction(Figure
2).
 |
When a BRM is received:
|
|
|
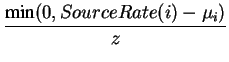 |
|
|
|
|
|
|
|
|
|
|
The VCShareis used to achieve an unit overload. When the network reaches steady state the VCShareterm converges to
ExcessFairshare(i), achieving the generalized fairness criterion. The complexity of the computations done at the switching interval is
![]() . The update operation when the BRM cell arrives is an O(1) operation. Proof of convergence of algorithm A, is given in the appendix.
. The update operation when the BRM cell arrives is an O(1) operation. Proof of convergence of algorithm A, is given in the appendix.
Simulation configurations We use different configurations to test the performance of the modified algorithm. We assume, unless specified otherwise, that the sources are greedy, i.e., they have infinite amount of data to send, and always send data at ACR. In all configurations the data traffic is unidirectional, from source to destination. If bidirectional traffic is used, similar results will be achieved, except that the convergence time will be longer since the RM cells in the backward direction will travel along with the data traffic from destination to source. All the link bandwidths are 149.76 (155.52 less the SONET overhead), expect in the GFC-2 configuration.
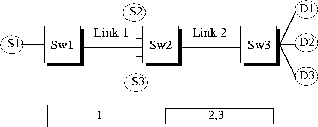
Three sources This is a simple configuration in which three sources send data to three destinations over a two switches and a bottleneck link (Figure 3). This configuration is used to demonstrate that the modified switches algorithm can achieve the general fairness for different set of weight functions.
Source bottleneck In this configuration (Figure 4), the source S1, is bottlenecked at 10 Mbps, which is below its fairshare (50 Mbps). This configuration tests whether the GW fairness can be achieved in the presence of source bottleneck.
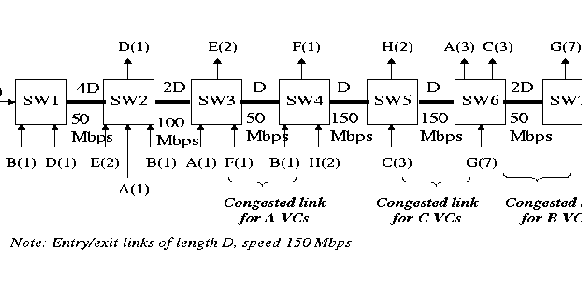
Generic fairness configuration - 2 (GFC-2) This configuration (explained detailedly in [ 20]) is a combination of upstream and parking lot configuration (Figure 5). In this configuration all the links are bottlenecked links, round trip times are different for different type of VCs.
 |
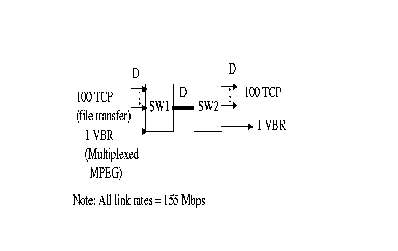
TCP sources with VBR background This configuration is used to test the robustness and scalability of the algorithm (Figure 6. In this configuration hundred infinite TCP sources (large file transfers) transmit data continuously through a bottleneck link to hundred destinations. One VBR connection carrying multiplexed MPEG traffic, which is long-range dependent, is used as background traffic [ 21]. The mean bandwidth of VBR traffic is 45 Mbps. The VBR traffic is generated with hurst parameter (H) value of 0.9, hence it has high degree of self-similarity.
 |
Simulation parameters
The simulations were done on an extensively modified version of NIST simulator [ 22]. The following parameter values were used in all our simulations: Link distance = 1000 Km; Averaging interval = 5 ms; Target delay = 1.5 ms; Exponential decay factor = 0.1 (when using dynamic queue control function).
The ``Averaging Interval'' is the period for which the switch monitors various parameters. Feedback is given based on these monitored values. The ERICA+ algorithm uses dynamic queue control to vary the available ABR capacity dependent on queue size. At steady state the queue length of constant value can be obtained. The ``Target Delay'' parameter specifies the desired delay due to this constant queue length at steady state. When using dynamic queue control function we exponentially average ExcessFairshareterm. This is done so that effectively only one feedback is given in each feedback interval and to absorb the variation in ``Target ABR Cap'' value due to the queue control function. For convergence, the feedback delay, averaging interval and exponential averaging decay factor should obey the following equation:
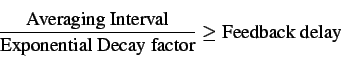
Simulation results In this section we give the simulation results for the different configurations. The simulations results using both constant queue control function (shown in graphs as configuration name and CQF) and dynamic queue control function (shown in graphs as configuration and DQF) are shown in the graphs. For the CQF the value of Fractionused is 0.9. The tabular results are those obtained from simulations using the dynamic queue control function.
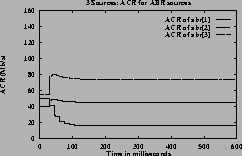
Three sources Simulations using a number of weight functions were done using the simple three sources configuration to demonstrate that GW fairness is achieved in all these cases. The ICRs (initial cell rate) of the sources were set to the (50,40,55) Mbps in all the simulations.
| Expected | ||||||
| Case | Src | mcr | a | wt | fair | Actual |
| # | # | func. | share | share | ||
| 1 | 1 | 0 |
|
1 | 49.92 | 49.92 |
| 2 | 0 |
|
1 | 49.92 | 49.92 | |
| 3 | 0 |
|
1 | 49.92 | 49.92 | |
| 2 | 1 | 10 |
|
1 | 29.92 | 29.92 |
| 2 | 30 |
|
1 | 49.92 | 49.92 | |
| 3 | 50 |
|
1 | 69.92 | 69.92 | |
| 3 | 1 | 10 | 5 | 15 | 18.54 | 18.53 |
| 2 | 30 | 5 | 35 | 49.92 | 49.92 | |
| 3 | 50 | 5 | 55 | 81.30 | 81.30 |
The allocations of these cases using DQF are given in Table 1. The following can be observed from the Table 1
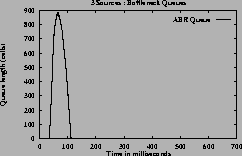
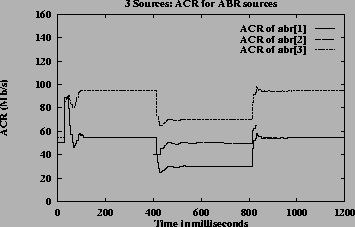
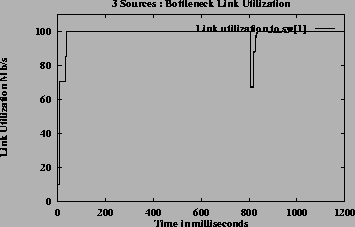
Figure 7shows the ACRs, queue and utilization graphs of the three sources for case 3 using constant queue control function. Figure 8shows the corresponding graphs using dynamic queue control function. From the figures one can observe that the sources achieve the GW fairness rate and queues are controlled in steady state queue. When using DQF, queue length values oscillate before reaching steady state values. The utilization achieved at steady state is 100% when using DQF and 90% (same as Fractionvalue) when using CQF.
Three sources: transient In these simulations the same simple three source configuration is used. Source-1 and source-3 transmit data throughout the simulation period. Source-2 is a transient source, which starts transmitting at 400 ms and stops at 800 ms. The total simulation time is 1200 ms. Same parameters values from the cases 1, 2 and 3 of the previous section were used in these simulations. The results of these simulations are given in Table 2. The non-transient (ntr) columns give the allocation when transient source-2 is not present, i.e., between 0ms to 400ms and between 800 ms to 1200 ms. The transient (tr) column give allocation when the transient source-2 is present, i.e., between 400 ms to 800 ms.
The ACR values of the sources and the utilization of the bottleneck link for case 2 are shown in figure 9. It can be seen both from the Table 2and the graphs that the switch algorithm does converge to the general fairness allocation even in the presence of transient sources. The algorithm has a good response time, since there is only a small dip in the utilization graph when the transient source stops sending traffic (at 800 ms).
Source bottleneck
Cases 1, 2 and 3 of section 8.1were simulated using the three sources bottleneck configuration. The total simulation time was 800 ms. In these simulations the source S1 is bottlenecked at 10 Mbps for first 400 ms, i.e., it always transmits data at rate of at most 10 Mbps, irrespective of its ACR (and ICR). After 400 ms, source S1 behaves like an infinite source and sends data at ACR.
|
The initial ICRs were set to 50, 30, 110 Mbps. The load on the bottleneck link is near unity. If the switch algorithm uses the CCR (current cell rate) value indicated in the RM cell as the source rate the switch cannot estimate the correct value of source rate of the bottleneck source. But if the switch uses measured source rate then it can correctly estimate the bottlenecked source's rate. Table 3shows the results both when the switch uses the CCR field and when it measures the source rate during the presence of source bottleneck (i.e., before 400 ms). The correct fairness is achieved only when the measured source rates are used. When the source bottleneck disappears after 400 ms, the sources achieve the GW fairness (fairshare value same as in the simple configuration), both when CCR is used as source rate and when source rates are measured.
| Exp | Actual | Exp | Actual | |||
| Src | wt. | frshr | (ntr) | frshr | (tr) | |
| # | # | func. | (ntr) | share | (tr) | share |
| 1 | 1 | 1 | 74.88 | 74.83 | 49.92 | 49.92 |
| 2 | 1 | NC | NC | 49.92 | 49.92 | |
| 3 | 1 | 74.88 | 74.83 | 49.92 | 49.92 | |
| 2 | 1 | 1 | 54.88 | 54.88 | 29.92 | 29.83 |
| 2 | 1 | NC | NC | 49.92 | 49.92 | |
| 3 | 1 | 94.88 | 95.81 | 69.92 | 70.93 | |
| 3 | 1 | 15 | 29.92 | 29.23 | 18.53 | 18.53 |
| 2 | 35 | NC | NC | 49.92 | 49.92 | |
| 3 | 55 | 119.84 | 120.71 | 81.30 | 81.94 |
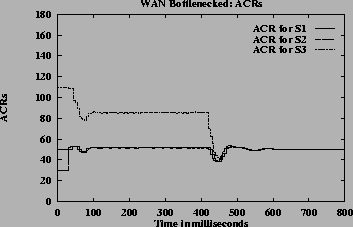
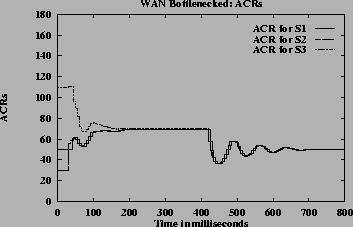
Figure 10 (a) shows the ACR graph for the simulation of case 1 using source rate from the CCR field of RM cell. Figure 10 (b) shows the same case using measures source rates. When the CCR value from the RM cells is used as source rate, the algorithm is not able to estimate the actual rate at which the source is sending data. So, it does not estimate the correct GW fairshare values in presence of source bottlenecks. When measured source rate is used it calculates correct fairshare even in the presence of source bottlenecks.
Link bottleneck: GFC-2
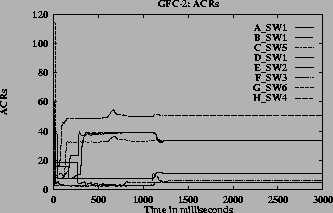
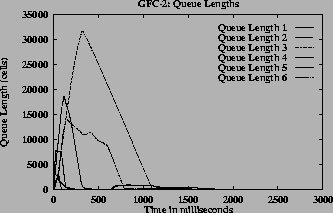
In this configuration each link is a bottleneck link. A MCR value of 5 was used for all A type VCs. All other VC's have MCR of 0. The MCR plus equal share of excess bandwidth was chosen as the fairness criteria. Dynamic queue control function was used in this simulation. The expected share for VCs of type A, B, C, D, E, F, G, H are 11.25, 5, 33.75, 33.75, 33.75, 6.25, 5, and 50.625 Mbps respectively. The actual allocation for these VCs in the simulation was 11.25, 5, 35.67, 35.75, 35.75, 6.25, 5, and 50.5 Mbps respectively, which agree well with the expected allocations. Figure 11 (a) shows the ACR graphs for each type of VCs. Figure 11 (b) shows the queue length graph at various bottleneck links between the switches. From the Figure and actual allocations it can be seen that the VCs converge to their expected fairshare. The queue length graphs show that initial queue buildup occurs before convergence and its maximum queue length depends on ICR (initial cell rate) and round trip time. This simulation demonstrates that the algorithm works in the presence of multiple link bottlenecks and different round trip times.
| Exp | Using | Using | |||
| Case | Src | wt. | frshr | CCR | Measured |
| # | # | func. | in RM cell | CCR | |
| 1 | 1 | 1 | 69.92 | 51.50 | 69.29 |
| 2 | 1 | 69.88 | 51.80 | 69.29 | |
| 3 | 1 | 69.88 | 85.94 | 69.29 | |
| 2 | 1 | 1 | 39.88 | 43.98 | 39.58 |
| 2 | 1 | 59.88 | 52.06 | 59.57 | |
| 3 | 1 | 79.88 | 85.85 | 79.76 | |
| 3 | 1 | 15 | 19.96 | 42.72 | 19.19 |
| 2 | 35 | 53.32 | 51.62 | 53.28 | |
| 3 | 35 | 86.64 | 86.16 | 86.37 |
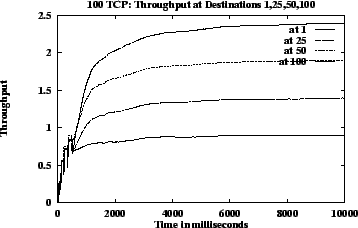
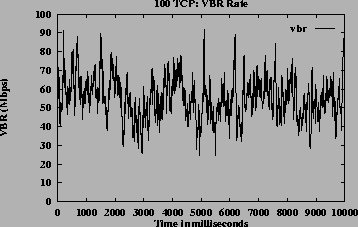
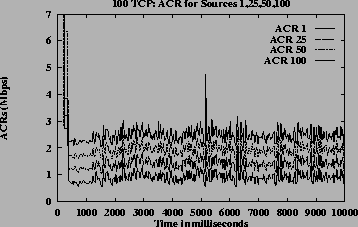
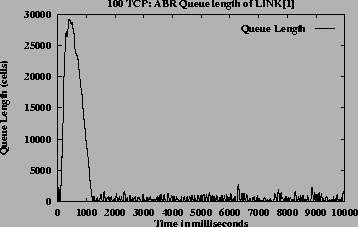
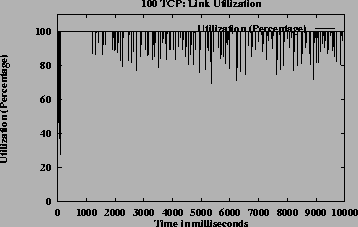
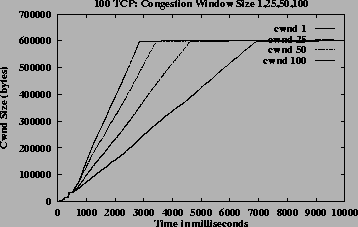
Figures 12 (b), (c) and (d) show ACRs, queue length and link utilization respectively, which are ATM level metrics. Figures 12 (e) and (f) show congestion window and average throughput respectively, which are TCP level metrics. Though the system does not have a steady state the queues are controlled and utilization is high. They expected throughput received by the TCP sources when congestion window is maximum, is 1.02 Mbps for source 1, 1.54 Mbps for source 25, 2.07 Mbps for source 50 and 2.59 Mbps for source 100 according to the GW fairness criteria (MCR plus proportional MCR in this case). The average throughput values as shown in Figure 12 (f) is slightly different from the expected throughputs. This is due to the varying VBR capacity and since the average throughputs include measurement during initial burstiness of TCP sources, where the congestion windows have not yet reached the maximum value. This simulation demonstrates that the algorithm is robust and scalable.
|
Conclusion In this paper, we have given a general definition of fairness, which inherently provides MCR guarantee and divides the excess bandwidth proportional to predetermined weights. Different fairness criterion such as max-min fairness, MCR plus equal share, proportional MCR can be realized as special cases of this general fairness. We showed how to realize a typical pricing policy by using appropriate weight function. The GW fairness can be achieved by using the ExcessFairshareterm in switch algorithms. The weights are multiplied by the activity level when calculating the ExcessFairshareto reflect the actual usage of the source.
We have shown how ERICA+ switch algorithm can be modified to achieve this general fairness. The proof of convergence of algorithm A is given in the appendix. The simulations results show that the modified algorithm achieves the general fairness in all configurations. In addition, the results show that the algorithm converges in the presence of both source and link bottleneck and is quick to respond in the presence of transient sources. In source bottlenecked configuration the value of the CCR (source rate) from the RM cells maybe incorrect. Hence, it is necessary to used the measured source rate in the presence of source bottlenecks. The algorithm is robust and scalable as demonstrated by simulation results using the hundred TCP sources plus VBR background configuration. Future work includes, extending the GW fairness criterion to multipoint ABR connections and designing a robust and scalable switch algorithm for such connections.
Proof:The proof technique used here is similar to the one used in [
6]. Let lbbe the link which is bottlenecked. Without loss of generality assume that first ksessions through the link lbare bottlenecked (either link bottlenecked or source bottlenecked) elsewhere. Let
![]() . Let
. Let
![]() be the bottleneck rates and
be the bottleneck rates and
![]() be the rates of non-bottlenecked (under-loaded) sources. Let
be the rates of non-bottlenecked (under-loaded) sources. Let
![]() be total capacity of bottlenecked links. These non-bottlenecked sources are bottlenecked at the current link lb. According to the GW fairness definition, fair allocation rates giis given by:
be total capacity of bottlenecked links. These non-bottlenecked sources are bottlenecked at the current link lb. According to the GW fairness definition, fair allocation rates giis given by:
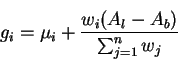
Assume that the bottlenecks elsewhere have been achieved, therefore the rates
![]() are stable. For simplicity, assume that the MCRs of these sources are zero. Proof for the bottlenecks having non-zero MCRs is a simple extension.
are stable. For simplicity, assume that the MCRs of these sources are zero. Proof for the bottlenecks having non-zero MCRs is a simple extension.
We show that rates allocated at this switch converges to
![]() and
and
![]() and load factor converges to z= 1.
and load factor converges to z= 1.
Case 1:Load factor z< 1. Here the link is under-loaded, hence due to the VCShareterm
![]() , all the rates increase. If n= 0, i.e. all the sessions across this link are bottlenecked elsewhere, there are no non-bottlenecked sources, the GW fair allocation is trivially achieved. Assume that
, all the rates increase. If n= 0, i.e. all the sessions across this link are bottlenecked elsewhere, there are no non-bottlenecked sources, the GW fair allocation is trivially achieved. Assume that
![]() , now because of the VCShareterm (in step for calculating
ERin Algorithm A), the rates of non-bottlenecked sources increase. This continues till load factor reaches a value greater than or equal to one. Hence we have shown that if load factor is less than one, the rates increase till the load factor becomes greater than one.
, now because of the VCShareterm (in step for calculating
ERin Algorithm A), the rates of non-bottlenecked sources increase. This continues till load factor reaches a value greater than or equal to one. Hence we have shown that if load factor is less than one, the rates increase till the load factor becomes greater than one.
Case 2:Load factor z> 1. In this case if the link is not getting its ExcessFairsharethen, its rate increases, which might further increase z. This continues till all the sessions achieve at least their ExcessFairshare. At this point the allocation rates are decreased proportional to 1/zdue to the first term. As in the previous case the zdecreases, till it reaches a value of 1 or less.
From the above two cases it can be seen that load factor oscillates around one and converges to the value of one. Assume that load factor is
![]() , then the number round trip times for it to converge to one is given by
, then the number round trip times for it to converge to one is given by
![]() . Henceforth, in our analysis we assume that the network is near the steady state that is load
factor is near one. This implies that
. Henceforth, in our analysis we assume that the network is near the steady state that is load
factor is near one. This implies that
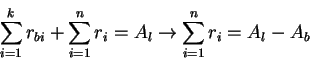
Let
![]() be the total allocation for MCRs of the non-bottlenecked sources. Define
be the total allocation for MCRs of the non-bottlenecked sources. Define
![]() , then we have:
, then we have:
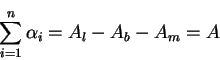
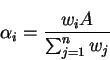
Case A:n= 0, i.e., there are no bottleneck sources. From the step for calculating
ERin Algorithm A, we have:
We observe that this equation behaves like a differential equation in multiple variables [
23]. The behavior is like that of successive values of root acquired in the Newton-Ralphson method for finding roots of a equation. Hence the above equation converges, and the stable values of
![]() is given by:
is given by:
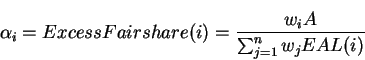
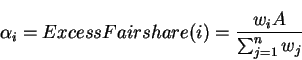
Case B:
![]() , i.e., there are some bottleneck sources. Let
, i.e., there are some bottleneck sources. Let
![]() be the allocated rate corresponding to rbi. Let wbibe the weight for session sbi. Let
be the allocated rate corresponding to rbi. Let wbibe the weight for session sbi. Let
![]() and
and
![]() . We know that the equation for the rate allocation behaves as a stabilizing differential equation. In the steady state all the above terms such as W, Wband rates stabilize. For sources bottlenecked elsewhere the algorithm calculates a rate
. We know that the equation for the rate allocation behaves as a stabilizing differential equation. In the steady state all the above terms such as W, Wband rates stabilize. For sources bottlenecked elsewhere the algorithm calculates a rate
![]() which is greater than rbi, otherwise the bottlenecked session would be bottlenecked at the current link. For non-bottlenecked source the rate at steady state is given by:
which is greater than rbi, otherwise the bottlenecked session would be bottlenecked at the current link. For non-bottlenecked source the rate at steady state is given by:
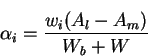
Since the link has an overload of one at steady state we have
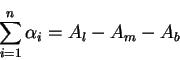
which implies that
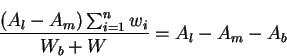
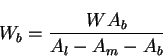
Using the above value for Wbwe get:
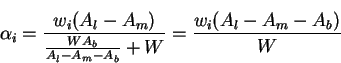
which is the desired values for the
![]() . Hence, the sessions bottlenecked at the link lbdo indeed achieve the GW fairness.
. Hence, the sessions bottlenecked at the link lbdo indeed achieve the GW fairness.
![]()
Proof:The convergence of the distributed algorithm similar to the centralized algorithm. Assume that the centralized algorithm converges in Miterations. At each iteration there are set of links
![]() which are bottlenecked at the current iteration.
which are bottlenecked at the current iteration.
![]() .
.
Using lemma 1, we know that each link
![]() does indeed converge to the general fair allocation
does indeed converge to the general fair allocation
![]() . The distributed algorithm converges in the above order of links until the whole network is stable and allocation is
. The distributed algorithm converges in the above order of links until the whole network is stable and allocation is
![]() . The number of round trips taken to converge is bounded by
. The number of round trips taken to converge is bounded by
![]() , since each link takes
, since each link takes
![]() round trips for convergence.
round trips for convergence.
![]()
 [Queue length]
[Queue length]
 [Utilization]
[Utilization]
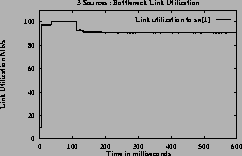
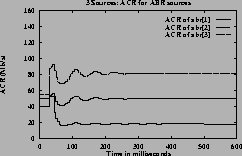 [Queue length]
[Queue length]
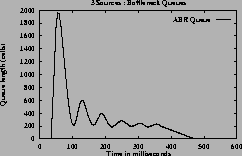 [Utilization]
[Utilization]
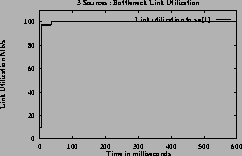
 [Utilization]
[Utilization]
 [Case 3 + DQF + measured source rate]
[Case 3 + DQF + measured source rate]
 [Queue graphs at different links]
[Queue graphs at different links]
 [ACRs]
[ACRs]
 [Link utilization]
[Link utilization]
 [Average TCP throughput]
[Average TCP throughput]