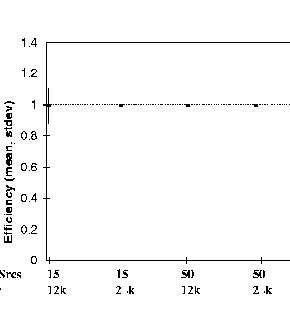
Rohit Goyal, Raj Jain, Sonia Fahmy, Bobby Vandalore, Shivkumar Kalyanaraman
2
Department of Computer and Information Science, The Ohio State
University
395 Dreese Lab, 2015 Neil Avenue
Columbus, OH
43210-1277, U.S.A.
E-mail: {goyal,jain}@cse.wustl.edu
Abstract: We describe proposed enhancements to the ATM Unspecified Bit Rate (UBR) service that guarantee a minimum rate at the frame level to the UBR VCs. These enhancements have been called Guaranteed Frame Rate (GFR). In this paper, we discuss the motivation, design and implementation issues for GFR. We present the design of buffer management and tagging mechanisms to implement GFR. We study the effects of policing, per-VC buffer allocation, and per-VC queuing on providing GFR to TCP/IP traffic. We conclude that when the entire link capacity is allocate to GFR traffic, per-VC scheduling is necessary to provide minimum throughput guarantees to TCP traffic. We examine the role of frame tagging in the presence of scheduling and buffer management for providing minimum rate guarantees.
Keywords: ATM networks, UBR, GFR, traffic management, congestion control, buffer management.
Guaranteed Frame Rate has been proposed in the ATM Forum to ensure minimum rate guarantees to UBR VCs. The rate guarantee is provided at the frame level. GFR also guarantees the ability to share any excess capacity fairly among the GFR VCs. In this paper, we describe the various options available to the network to provide minimum rate guarantees to the UBR traffic class. We discuss the GFR proposals and outline the basic characteristics of GFR.
We explore three different mechanisms - policing, buffer management, and scheduling - for providing minimum guarantees to TCP traffic. We conclude that per-VC scheduling (fair queuing) is necessary to ensure minimum rate guarantees at the TCP level. We also discuss the dynamics of the interactions of per-VC scheduling with buffer management and policing. In this paper, we present simulation results for infinite TCP traffic.
The original GFR proposals [ 1 1, 1 2] provide the basic definition of the GFR service. GFR provides a minimum rate guarantee to the frames (not cells) of a VC. The guarantee requires the specification of a maximum frame size known as the Common Part Convergence Sublayer Service Data Unit (CPCS-SDU). This means that if the user sends packets 3 smaller than the CPCS-SDU size, at a rate less than the minimum guaranteed rate, then all the packets are expected to be delivered by the network with minimum loss. If the user sends packets at a rate higher than the minimum guaranteed rate, it should still receive at least the minimum rate. In addition, all packets sent in excess of the minimum rate should receive a fair share of any unused network capacity.
The three mechanisms for providing per-VC minimum rate guarantees are:
The corresponding GCRA algorithm is outlined below. This definition describes a continuous state version of the leaky bucket algorithm [ 2 ]. The GCRA parameters are the Interval I = 1/MCR, and the Limit L = CDVT + BT/2 where BT = (MBS - 1)(1/MCR-1/PCR). Here BT is the burst tolerance corresponding to the maximum burst size (MBS). This specifies the token bucket depth in time units. CDVT is the cell delay variation tolerance associated with the rate. In the case of GFR, the tolerance in MCR is minimal, and the CDVT value is expected to be small. MBS is defined as twice the maximum frame size that can be sent by the application using the GFR connection. Recently, the GCRA parameters have been changed by the ATM Forum. The MBS parameter has been separated from the Maximum Frame Size (MFS), and separate algorithms are used for MBS, MFS and PCR conformance. Conformance to MCR is tested by yet another GCRA mechanism that determines the eligibility of the frame for receiving MCR guarantees. The implementation of the new conformance and eligibility mechanisms is a topic of future research.
Let the first cell of a frame arrive at time t. Let X be the value of the leaky bucket counter, and LCT be the last compliance time of a cell. Initially X = LCT = 0.
When the first cell of a frame arrives (at time t):
X1 := X - (t - LCT) IF (X1 < 0) THEN X1 := 0 CELL IS CONFORMING TAGGING := OFF ELSE IF (X1 > BT/2 + CDVT) THEN CELL IS NON-CONFORMING TAG CELL TAGGING := ON ELSE CELL IS CONFORMING TAGGING := OFF ENDIF IF (CELL IS CONFORMING) X := X1 + I LCT := t ENDIF
IF (TAGGING == ON) THEN TAG CELL ELSE CELL IS CONFORMING X1 := MAX(X - (t - LCT), 0) X := X1 + I LCT = t ENDIF
An exception can be made for the last cell of the frame (e.g., EOM cell for AAL5 frames). Since the last cell carries frame boundary information, it is recommended that the last cell should not be dropped unless the entire frame is dropped. For this reason, a network may choose not to tag the last cell of a frame. In our implementation, we do not drop or tag the last cell.
When a network element sees a tagged frame, it cannot tell if the frame was tagged by the source end system or an intermediate network. This has significant influence on providing rate guarantees to the CLP0 stream, and is further discussed in section 3.2.
The original GFR proposal [ 1 1] outlined two possible techniques for providing minimum rate guarantees to UBR VCs:
It was shown by [ 3 ] that for TCP traffic, it is difficult to provide end to end rate guarantees with tagging and FIFO queuing. A combination of large frame size and a low buffer threshold (at which tagged frames are dropped) is needed to provide minimum rate guarantees. This is undesirable because low thresholds result in poor network utilization.
It is also clear that per-VC queuing together with per-VC buffer management can provide minimum rate guarantees. However, it was unclear at this point, if the addition of per-VC buffer management to FIFO queuing with per-VC policing (tagging) would be enough provide the necessary rate guarantees. Also, with per-VC queuing, the role of tagging needs to be studied carefully.
We designed a buffer allocation policy called Weighted Buffer Allocation (WBA) based on the policies outlined in [ 8 ]. This policy assigns weights to the individual VCs based on their MCRs. The weights represent the proportion of the buffer that the connection can use before its frames are subject to discard. The WBA policy is described below.
When a the first cell of a frame arrives on a VC, if the current buffer occupancy (X) is less than a threshold (R), then the cell and the remaining cells of the frame are accepted. If the buffer occupancy exceeds this congestion threshold, then the cell is subject to drop depending on two factors - is the cell tagged? and, is the buffer occupancy of that VC more than its fair share?
Under mild congestion conditions, if there are too few cells of a VC in the buffer, then an attempt is made to accept conforming cells of that VC. As a result, if the VC's buffer occupancy is below its fair share, then a conforming (untagged) cell and the remaining cells of the frame are accepted, but a tagged cell and the remaining cells of the frame (except the last) are dropped. In this way, at least a minimum number of untagged frames are accepted from the VC.
If the buffer occupancy exceeds the mild congestion threshold, and the VC has at least its share of cells in the buffer, then the VC must be allowed to fairly use the remaining unused buffer space. This is accomplished in a similar manner as the schemes in [ 8 ], so that the excess buffer space is divided up equally amongst the competing connections.
The switch output port consists of a FIFO buffer for the GFR class with the following attributes:
When the first cell of a frame arrives:
IF (X < R) THEN ACCEPT CELL AND FRAME ELSE IF (X > R) THEN IF ((Li < R*Wi) AND (Cell NOT Tagged)) THEN ACCEPT CELL AND FRAME ELSE IF ((Yi - R*Wi)*Na < Z*(X-R)) THEN ACCEPT CELL AND FRAME ELSE DROP CELL AND FRAME (except the EOM cell) ENDIF ENDIF
Further drop policies like EPD can also be used to drop all frames in excess of a more severe congestion threshold on top of the WBA threshold R. In our simulations we do not use EPD with WBA.
Per-VC buffer management can be effectively used to enforce tagging mechanisms. If the network does not perform tagging of VCs, but it uses the tagging information in the cells for traffic management, then per-VC accounting of untagged cells becomes necessary for providing minimum guarantees to the untagged (CLP0) stream. This is because, if a few VCs send excess traffic that is untagged, and no per-VC accounting is performed, then these VCs will have an excess number of untagged cells than their fair share in the buffer. This will result in conforming VCs (that tag all their excess traffic) receiving less througput than their fair share.
The conforming VCs will experience reduced throughput because the non-conforming but untagged cells of the overloading VCs are not being isolated. This is the case even if per-VC queuing in a shared buffer is performed. If all VCs share the buffer space, then without per-VC buffer management, the overloading VCs will occupy an unfair amount of the buffer space, and may cause some conforming frames of other VCs to be dropped. Thus, no matter how frames are scheduled (per-VC or FIFO), if the switch allows an unfair distribution of buffer occupancy, then the resulting output will also be unfair.
If a network does not tag the GFR flows, its switches should not use the information provided by the CLP bit unless they implement per-VC buffer management. We will show in section 5 that with only per-VC queuing and EPD (without per-VC buffer management or policing), a switch can provide rate guarantees for the CLP0+1 flow, but not for the CLP0 flow.
To provide rate guarantees to the CLP0 flow, per-VC accounting of the CLP0 flow must be performed along with per-VC scheduling. This protects the network from overloading sources that do not tag their excess traffic.
We implement a Weighted Fair Queuing like service discipline to provide the appropriate scheduling. The details of the discipline will be discussed in a later paper. The results of our simulations are discussed in section 5.
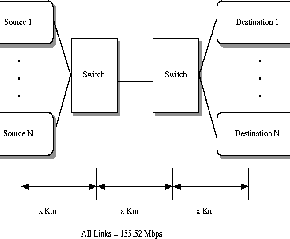
Most of our simulations use 15 sources. We also perform some simulations with 50 sources to understand the behavior with a large number of sources.
Link delays are 5 milleseconds. This results in a round trip propagation delay of 30 milliseconds. The TCP segment size is set to 1024 bytes. For this configuration, the TCP default window of 64K bytes is not sufficient to achieve 100% utilization. We thus use the window scaling option to specify a maximum window size of 600,000 Bytes.
All link bandwidths are 155.52 Mbps, and peak cell rate at the ATM layer is 149.7 Mbps after the SONET overhead. The duration of the simulation is 20 seconds. This allows for adequate round trips for the simulation to give stable results.
In our simulations, the end systems do not perform any tagging of the outgoing traffic. We measure performance by the end to end effective throughput obtained by the destination TCP layer. The goal is to obtain an end-to-end througput as close to the allocations as possible. Thus, in this paper we look at the aggregrate CLP0+1 flow.
Figure 3 plots the average efficiencies of the 4 simulation experiments. For the 15 (50) source configurations, each source has a maximum expected throughput of about 8.2 (2.5) Mbps. The actual achieved throughput is divided by 8.2 (2.5) , and then the mean for all 15 (50) sources is found. The point plotted represents this mean. The vertical lines show the standard deviation below and above the mean. Thus, shorter standard deviation lines mean that the actual throughputs were close to the mean. Standard deviation is an indicator of the fairness of the sources' throughputs. A smaller standard deviation indicates larger fairness.
In figure 3, all TCP throughputs are within 20% of the mean. The mean TCP throughputs in the 15 source configuration are about 8.2 Mpbs for both buffer sizes. For 50 sources, the mean TCP throughputs are about 2.5 Mbps. The standard deviation from the mean increases with increasing buffer sizes for the 15 source configuration. The increase in buffer sizes leads to more variability in the allocation, but as the number of sources increases, the allocation reduces, and so does the variability. All configurations exhibit almost 100% efficiency, and the fairness for large number of sources is high. From this we conclude that equal allocation of the available bandwidth for SACK TCP traffic to the CLP0+1 flow can be achieved by per-VC accounting only.
To achieve unequal allocations of end to end throughputs, we tried two options:
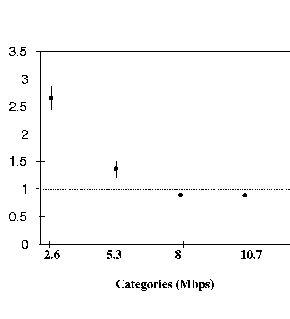
Figure 4 shows the resulting allocations obtained from the simulations for tagging and per-VC accounting. The 5 points represent the efficiencies obtained by the 5 categories of bandwidth allocations. The horizontal dotted line represents the target efficiency (100%) desired from the allocations. Thus, the average allocation of the first category was over 2.5 times its target allocation (2.6 Mbps), while the last category received 0.8 of its allocation (13.5). The dotted line represents the target efficiency for each category. The total efficiency (not shown in the figure) was almost 100%. The figure shows that the simple per-VC accounting presented here, with tagging cannot effectively isolate competing TCP traffic streams. We tried various drop thresholds R for WBA, and R = 0.5 achieved the best isolation. However, the achieved rates were not close to the target rates. This is especially true in cases like these where the entire link capacity has been allocated to the TCP connections. We have shown that with low to moderate utilization, per-VC accounting alone can provide unequal rate allocations to TCP/IP traffic. Under high link unilization, FIFO buffering with WBA together with tagging is not sufficient to provide GFR guarantees to TCP/IP traffic. This conclusion is also verified by [ 4 ] for a different per-VC buffer allocation policy.
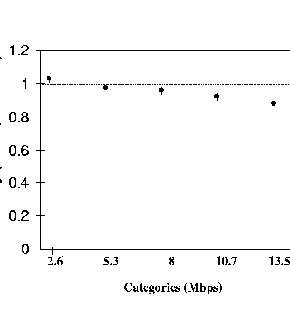
Figure 5 shows the resulting allocations obtained for the 15 source unequal rate configuration with per-VC scheduling without tagging or accounting. The figure shows that the achieved throughputs are close (within 10%) to the target throughputs for the CLP0+1 stream. Also, the total efficiency (not shown in the figure) is over 90% of the link capacity. From this, we conclude that per-VC queuing alone is sufficient to provide end to end minimum rate guarantees for infinite TCP traffic.
To provide rate guarantees to the CLP0 flow, per-VC accounting is needed to separate the CLP0 frames of the different VCs. If tagging is performed by the network on all the VCs, then per-VC accounting may not be necessary, and preferential dropping of tagged frames with per-VC scheduling should be sufficient. Simulation results of this configuration are currently under study.
The results so far
are summarized by table
1. The table
shows the eight possible options available with per-VC accounting,
tagging (by the network) and queuing. An ``X'' indicates that the
option is used, and a ``-'' indicates that it is not used. The GFR
column indicates if GFR guarantees can be provided by the combination
specified in the row.
| Acc- | Tag- | que- | GFR | Notes |
| ounting | ging | uing | GFR | Notes |
| - | - | - | No | Clearly |
| X | - | - | No | Equal allocation |
| - | X | - | No | [ 3 ] |
| X | X | - | No | |
| - | - | X | Yes | Only for CLP0+1 |
| X | - | X | Yes | |
| - | X | X | Yes | Under study |
| X | X | X | Yes | Also for CLP0 |