"Many that live deserve death. And some that die deserve life. Can you give it to them? Then do not be too eager to deal out death in judgement. For even the very wise cannot see all ends."
—Gandalf, The Fellowship of the Ring by J. R. R. Tolkien, Book 1, Chapter 2
Memory management is one of the fundamental operations required of any modern operating system kernel. In nearly all real world computer systems today, a layer of abstraction called virtual memory exists above the raw physical memory resources in the machine. Virtual memory provides a convenient abstraction that makes it both easier to develop portable applications, and easier for the kernel to isolate workloads from each other. However, these benefits are counter-balanced by some challenges, and designing a high performance virtual memory management system is a complex task that requires the kernel to make tradeoffs between different objectives.
In this lab, you will investigate two such objectives: (1) making memory allocation fast, and (2) ensuring high performance for workloads that require significant memory resources. You will study the tradeoff between these two objectives by implementing a kernel module that provides two different techniques for virtual memory management: (1) demand paging, and (2) allocation time paging (herein refered to as "pre-paging").
In this lab, you will:
mmap() system call to perform
virtual memory mappings for a process. Processes will interact with your
module via a special device file, in this case /dev/paging.
When a process issues the mmap() call to this file, your
module code will be invoked.
mmap call, and the runtime of a matrix multiplication application
that uses the memory you map for it.
For this lab you are encouraged to work with one or two other people as a team, though you may complete this assignment individually if you prefer. Teams of more than 3 people are not allowed for this assignment.
In this lab assignment, you will submit a report that unifies your observations and thoughts, and since part of the assignment will be to present graphs of results obtained from trials you will run to assess performance, you may choose to use a non-text file format (e.g., .docx or .pdf) for your report if you'd like. For more information please see "What to turn in" below.
Please complete the exercises described below. As you work through them, please take notes regarding your observations, and when you are finished please write-up a cohesive report and upload it along with your code files, graph files, etc. that are requested in the lab assignment to the appropriate assignment page on Canvas.
mmap() system call by executing man 2 mmap on linuxlab.
include/linux/mm.h and include/linux/mm_types.h for relevant kernel
data structures related to memory management.
You will be implementing a kernel module to
study kernel behaviors and design tradeoffs at the kernel level. The user level
component will interact with your kernel module by issuing system calls to a
special device file, /dev/paging.
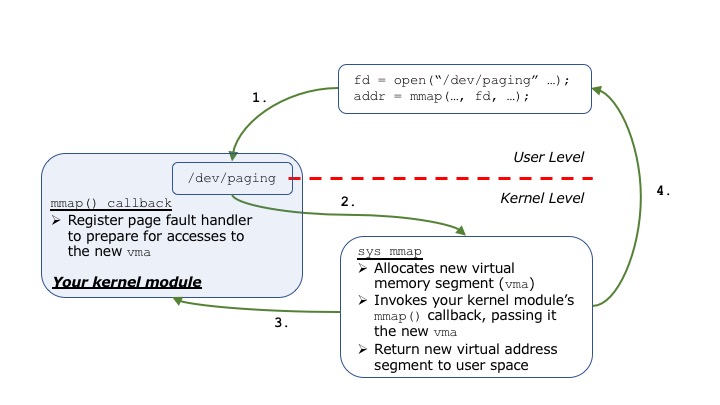
The ways in which your user user level and kernel level components interact are diagrammed in the image below.
As shown, your module will create the /dev/paging device file,
which a user process can access via the open() system call. Once
the user has a valid file descriptor with which to access your module, it can
then issue the mmap() system call in order to request the
allocation of new virtual memory segments. As the image above shows, when a
process issues mmap(), the kernel's system call handler first
inspects the arguments to the call, and if everything is valid it creates a
new virtual memory segment and stores the information in a data structure called
struct vm_area_struct (or just "vma" in Linux kernel
developer terminology). Because one of the arguments to the system call is a
file descriptor referencing the /dev/paging file, the kernel then
invokes a special function called a callback that allows your module to
perform some custom processing on the new vma before returning
the new virtual address to the user process.
In your module's mmap() callback, you will be implementing some
logic to map the new virtual address range specified by the vma to
actual physical memory. In the default mode, your callback will simply
register a custom page fault handler so that when the user process eventually
tries to access the new virtual address segment, a page fault will be triggered
by the hardware and the kernel will allow your handler to run. At that point, your
page fault handler will be responsible for allocating new physical memory, and
updating the process' page tables to map the vma to the new physical
memory that you allocated. This interaction is illustrated further via the image
below.
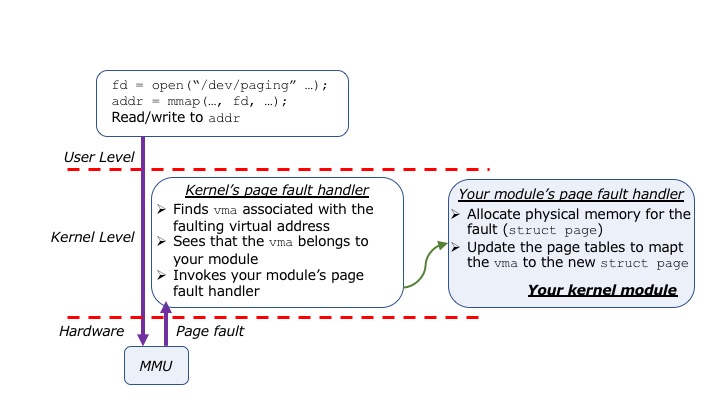
This mode of virtual memory management mirrors what Linux does for regular memory allocations, and is called demand paging. That is, physical memory is allocated asynchronously as new virtual memory segments are accessed by the process. However, in addition to this mode of operation, your module will also implement an alternative to demand paging (which we refer to as "pre-paging") where physical memory is allocated and page tables are updated directly during your module's mmap() callback. The code for these two modes of operation will be very similar, except that with pre-paging the page fault handler will never be invoked by the hardware because the process will always be accessing virtual addresses that already have valid virtual-to-physical address translations in the page tables.
The instructor has provided a
framework for your kernel module as well as a user and header file designed
to make it easy to get a basic version of your project up and running. In its initial
configuration, the kernel module creates the
/dev/paging device file, and registers an mmap()
callback that simply installs a no-op page fault handler when processes try to
allocate memory via the device file. This page fault handler does not perform
memory allocation or update page tables, but rather tells the kernel to abort
your program.
You should first download the code, compile the kernel module and the
dense_mm program, load the module and run the program.
Note that doing this should produce a bus error, since the module is not yet providing the memory management features that you will implement in the rest of this lab assignment.
Add a section to your project report titled "Initial Configuration"
and in that section please give the kernel dmesg output as well as the
output of the dense_mm program when executed on your
Raspberry Pi, and what you observed when you built and ran both of
those pieces of code.
mmap() callback and the
eventual invocation of our page fault handler. Our approach will be to use a
special pointer embedded in the vm_area_struct object called
vm_private_data; i.e., given a pointer "vma"
of type struct vm_area_struct *, this data structure can be
accessed as vma->vm_private_data. This field is of type void
* and allows us to allocate a pointer to an arbitrary data type in
the mmap() callback, store it in vma->vm_private_data,
and access it from the page fault handler.
For example, assume fn1 and fn2 are invoked on the
same vma, with fn1 being called before fn2. Then,
void fn1(struct vm_area_struct * vma)
{
// ...
void * ptr = x; // x being some dynamically allocated state
// ...
vma->vm_private_data = ptr;
}
void fn2(struct vm_area_struct * vma)
{
void * ptr = vma->vm_private_data;
// ptr now has the value 'x' assigned above
}
The state stored in this private data field is needed in order to remember what
physical memory has been allocated for a process. You are responsible for
designing a new struct data structure to track this information.
This data structure should be dynamically allocated in the mmap
callback, stored in the vm_private_data field of the VMA, and
eventually freed when the VMA is deleted. It is up to you to determine
precisely what information should be stored in this data structure. The only
constraints are the following:
atomic_t) in it. struct
page *) allocated in your page fault handler must ultimately be freed.
Finally, we need to update the two remaining callbacks that the kernel can
invoke on our vma: when a new vma is created as a
copy of an existing vma, the kernel invokes the open
callback, and when a vma is being deleted, the kernel invokes the close
callback. The open callback should simply retrieve a pointer to our new
data structure via vma->vm_private_data and increment the reference count
of its atomic variable. Note: the vmas you use in this assignment are not (always)
created by your page fault handler, so the open callback may not
be invoked. So, you will need to initialize the value of your reference count to 1 in
your mmap call. The close callback should retrieve your data
structure, decrement its reference count, and if it becomes zero, free the dynamically
allocated memory.
Add a new section to your report titled "Datatype Design" and in it describe how you designed this datatype, and explain what information it tracks. Note that you may not be able to complete this explanation until you finish parts 3 and 4 of this lab assignment.
alloc_page.
remap_pfn_range:
remap_pfn_range(struct vm_area_struct * vma, unsigned long vaddr, unsigned long pfn, unsigned long length, vm_flags_t pg_prot);
This function updates the page tables to map the virtual address (starting at
vaddr) to the physical address (starting at page frame
pfn), for length bytes with access bits as specified in
pg_prot. The first, fourth, and fifth values will be the same for every invocation of the
function: vma, PAGE_SIZE, and vma->vm_page_prot, while the second and third
arguments will vary based on the faulting address and the page frame number that you allocated.
For this step, you may find the following functions/macros valuable:
PAGE_ALIGN(addr): get the page-aligned address for a virtual
address (i.e., round an address down to the nearest 4KB boundary)
page_to_pfn(struct page *): determine the page frame number for a struct page *
VM_FAULT_NOPAGE (this sounds like an error return, but it tells the kernel that your callback has
internalized memory allocation and page table management)
alloc_page, return VM_FAULT_OOM
VM_FAULT_SIGBUS
Once these steps are successfully completed, you should be able to run the
user-space dense_mm program to completion! However, note that in
its current state, our module has a serious memory leak, because we never free
the physical pages that are allocated via our page fault handler. However, at
this point it is a good idea to see if your program will run to completion.
Add a new section to your report titled "Page Fault Handler" and in it please
describe how you implemented the page fault
handler, including how you calculated the values for vaddr and
pfn to pass to remap_pfn_range. In that same section
of your report please also show the output given by your user-level
dense_mm program.
close callback function to appropriately:
__free_page();
This function should perform the above steps if and only if there are no remaining references
to our vma. We can do this by decrementing the reference count and checking whether or not
it is equal to 0.
Finally, add two new static atomic_t variables to your kernel
module (not associated with any vma or tracker structure, just static globals).
The first variable should be incremented by 1 every time you allocate a new
struct page, and the second variable should be incremented by 1
every time you free a struct page. In your module's exit function,
read these two values and print out their values. If your module is functioning
correctly, they should be equal.
Add a new section to your report titled "Close Callback" and in that section
please describe how you implemented the close callback.
After running the dense_mm program with an input of 256,
unload your module and print the number of pages that you allocated and freed.
mmap
callback. In this case, the page fault handler should never be invoked.
You should add a new module parameter to your kernel module called demand_paging as follows:
static unsigned int demand_paging = 1;
module_param(demand_paging, uint, 0644);
In this way, you can disable demand paging and enable "pre-paging" by
passing a value of 0 to demand_paging when you insert the module via insmod.
The implementation of pre-paging should be straightforward, because all of
the operations you need to do have already been performed in your page fault
handler. The main difference is that you will be allocating and mapping memory
for every page of virtual address space in the vma, rather than just
one page as you've done in the page fault handler.
There are two possible approaches to memory allocation for pre-paging:
alloc_pages() that gets all
of the pages you need in one call, and then
invokes remap_pfn_range one time to map the entire range, or
alloc_page and remap_pfn_range with
each iteration handling one page at a time.
As with demand paging, the behavior of the mmap call should be as follows (which will require your module to remember what happened during pre-paging):
Note: these instructions assume you've written a separate function in your kernel module that your mmap callback function invokes to perform pre-paging.
VM_FAULT_NOPAGE, your mmap callback should return 0, and the mmap call in userspace will automatically return the address of the new mapping
alloc_page or alloc_pages) failed, the function your mmap callback invokes should return VM_FAULT_OOM, your mmap callback should return -ENOMEM and the mmap call in userspace will then return MAP_FAILED (and errno will automatically set to ENOMEM)
VM_FAULT_SIGBUS, your mmap callback should return -EFAULT and the mmap call from userspace will return MAP_FAILED (with errno automatically set to EFAULT)
Add a new section to your report titled "Pre-Paging" and in that section please describe how you implemented pre-paging, focusing especially on how you performed physical memory allocation.
dense_mm program to perform two timing measurements: the sum of the amount
of time taken to execute all three calls to mmap, and the amount
of time taken to perform the matrix multiplication. Insert calls to
gettimeofday to perform these measurements.
On your Raspberry Pi run representative trials that explore how the two different module modes perform: demand paging, and pre-paging. You should run the following sets of experiments in each mode:
dense_mm with a value of 64
dense_mm with a value of 128
dense_mm with a value of 256
dense_mm with a value of 512
Run each experiment 10 times to collect the minimum, maximum, mean, median, and standard deviation of the 10 runs, for both the mmap system call time and the matrix multiplication time.
Now, create three line graphs (e.g., using Excel or gnuplot), each with matrix size on the x-axis and (i) one with just system call performance on y-axis, (ii) one with just matrix multiplication time on the y-axis, and (iii) one with system call + matrix multiplication time on the y-axis. You may find it useful to format the axes in log-scale to make the graphs more readable, as runtime will increase exponentially in the matrix multiplication case with each separate value. Each data point on the plot should represent the mean and standard deviation (as error bars) of the 10 associated experiments -- if you can't figure out how to plot error bars, you can put standard deviation values in a separate table.
Please add a section titled "Experiments" to your report, and in it please give the minimum, maximum, mean, median, and standard deviation for the 10 runs in each experiment. In that same section please summarize your findings, including what the results you obtained say about the relative merits of demand paging and pre-paging (i.e., did one of them consistently outperform the other, or did they perform similarly, and were there any special conditions under which the performance differed?). In that section please give the names of the graph files you are turning in with those plots, and if you would like to use a non-text format please also feel free to include pictures of the plots within your discussion.
Your report file should include:
EXTRA CREDIT
For an additional 5% on this lab, select another user-level program of
interest to you, configure it to perform memory allocation via
/dev/paging, and perform the same analysis steps as above to
compare the system call latency with the performance of the application. Please
add another section at the end of your report titled "Extra Credit" and in it please
analyze whether the results differ across workloads, and if so please suggest reasons
why this is the case -- that is, what about the application's behavior or resource
requirements would explain the differences in performance results?